
 400-626-7377
400-626-7377
Python如何連接DB2數據庫?
今天我們來探討下Python如何連接DB2數據庫。DB2是IBM在美國開發的一組關系數據庫管理系統。它的主要操作環境是UNIX(包括IBM自己的AIX),Linux,IBM i(以前稱為OS/400),z/OS和Windows服務器版本。在工作中遇到了這種情況,該項目需要連接到IBM的關系數據庫(DB2),在這方面的數據庫相對較少,因此關于這方面數據庫的知識也并不多。其中,ibm_db是一個相對易于使用的庫。Internet上有一些教程,但這說的不是很準確,而且也不詳細,到處都是錯誤,沒有辦法只能在獲得源代碼之后對其進行分析,然后最終將其完成。

安裝
環境需求:
首先是數據庫DB2,下載連接直接百度,我下載是這兩個文件:
只下載箭頭所指即可,我還沒在linux上做測試。
數據庫API(這個東西找了好久,終于找到了合適的)(找不到搜:SQLAPI.zip)
Python2.7
VCForPython2.7
ibm_db(主要的庫,在安裝中會下載ntx64_odbc_cli庫,安裝時會檢測 IBM_DB_HOME 變量,所以需要安裝數據庫后再安裝ibm_db)
以上模塊在網上都可以找到,請自行下載安裝。
建庫
數據庫安裝好之后新建一個實例,默認是DB2,然后創建一個新的數據庫,我創建的MYTEST(在操作數據庫以及鏈接數據庫需注意大小寫),命令行方法:
打開命令行處理器:(管理員身份)
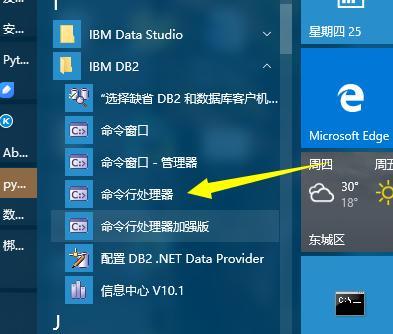
輸入?直接回車,會顯示命令列表,開啟數據庫管理器:
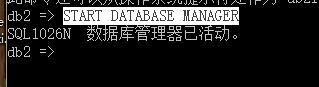
然后關閉就好,建立數據庫以及創建表還是使用db2 data studio,比較方便,安裝時在根目錄創建一個臨時目錄,把文件解壓進去,之后再修改install.exe的屬性,改成兼容Windows 7運行,同時使用管理員權限打開,之后就是安裝安裝好之后點擊左側新建一個數據庫。
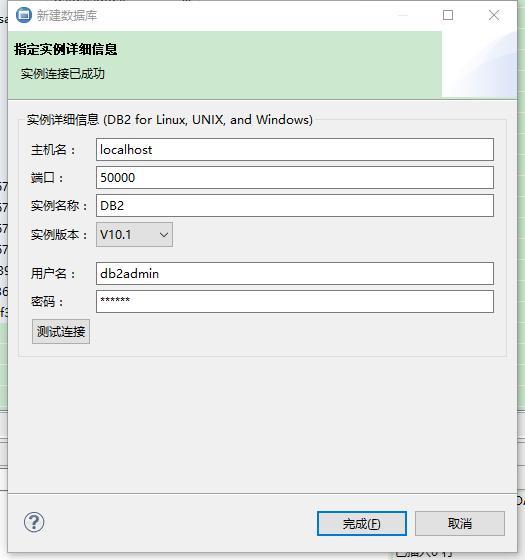
按以上方式填寫,用戶名和密碼使用安裝數據庫時設置的用戶名密碼。
實例配置好并且能測試成功就可以創建數據庫了。
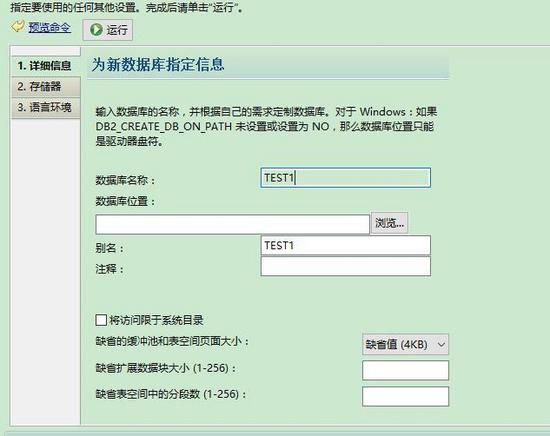
數據庫名稱和別名寫上即可,其余的由于是測試就不填了,等正式環境在考察下性能優化方面的配置。點擊運行創建,過程有點慢,不知道是不是機器配置原因,大概花了十幾分鐘。
下面就不詳細說建表的過程了,值需注意,建表前先簡歷模式(Schema),使用自定義模式建表。
連接
連接直接導入庫
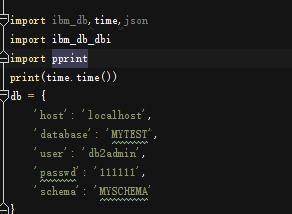
導入ibm_db_dbi即可。
import ibm_db_dbi
conn = ibm_db_dbi.connect(“PORT=50000;PROTOCOL=TCPIP;”, host=db[“hot”], database=db[“database”], user=db[“user”],
password=db[“passwd”])
conn.set_autocommit(True)
cursor = conn.cursor()
連接數據庫,設置自動提交
查詢
3sql = “select * from testable”
result = cursor.execute(sql)
注意,以上查詢方式是錯的。正確如下:
4sql = “select * from MYSCHEMA.TESTTABLE”
result = cursor.execute(sql) rows = cursor.fetchall()
這里的操作和MySQL沒什么差別了。
插入
3sql = “insert into MYSCHEMA.TESTTABLE (“uuid”, “content”) values (‘%s', %s)” % (“1234567890”, “asdfghjkl”)
result = cursor.execute(sql)
更新
5sql =“update ”MYSCHEMA”.”TESTTABLE ” set ”content”=‘%s' where ”uuid” = ‘%s'” % (“aaa”, “1234567890”)
result = cursor.execute(sql)
如果操作成功,result就是True,注意每個語句的引號,單雙必須按以上的方式。
以上就是Python如何連接DB2數據庫的全部內容了,想了解更多關于DB2數據庫的信息,請繼續關注中培偉業。
相關閱讀
- 數據庫安全關鍵技術之數據庫漏洞掃描技術01-05
- 分布式數據庫到底是什么?12-18
- 主流數據庫哪個最好?哪個現在最火?10-31
- 后端的數據庫用MySQL還是oracle10-17
- 為什么要關注數據庫兼容性09-23





-
全國報名服務熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377
京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377