
 400-626-7377
400-626-7377
【專家視點】大數據將促進分布式數據庫發展及去Oracle
本文全面介紹了分布式數據庫和它的設計理念,以及分布式數據庫的優勢和應用場景,從而引出OLTP領域使用分布式數據庫的考慮因素和分布式數據庫取代Oracle的常見應用方案,最終大數據應用促進了“分布式架構”的繁榮。
分布式數據庫簡介
分布式數據庫系統通常使用較小的計算機系統,每臺計算機可單獨放在一個地方,每臺計算機中都可能有DBMS的一份完整拷貝副本,或者部分拷貝副本,并具有自己局部的數據庫, 通過網絡互相連接共同組成一個完整的、全局的邏輯上集中、物理上分布的大型數據庫。
分布式并行數據庫通過并行使用多個CPU和磁盤來將諸如裝載數據、建立索引、執行查詢等操作并行化以提升性能的數據庫系統。其中最重要的關鍵詞是并行。
在組成大規模計算機集群的時候,通常有兩種特性要考慮:并行和分布式。并行強調多節點同時執行,共同解決一個大問題,通常在嚴格的高性能網絡環境中,有嚴格的執行要求和反饋時限。或者通過良好的分發極致,分布式并行處理不同的任務,從而達到數據處理高性能的需求。
因為并行數據庫的技術特點是為了某類需求設計的,因此它有自己的適用環境。它采用關系理論非常適合結構化數據。非結構化或者某些半結構化數據,當然也可以在其中存和取,但是實際上有很多更好的解決方案可以選擇。
并行數據庫目前的主要問題來自于它的設計目的,因為要實現完美的并行,因此它大多被設計為計算和存儲緊密耦合,這樣計算可以控制每行數據的存儲位置和每個數據塊的存儲格式,這樣對大型的任務而言提供了很好的性能。
分布式數據庫設計理念
分布式數據庫核心的理念可以用下面一句話來概括:
積少成多、讓多個“小”的能力協同、匯聚成“大”的能力來解決大問題,是引跑分布式數據庫最核心的設計理念。分布式數據庫的基本思想是將原來集中式數據庫中的數據以及處理能力,分散存儲到多個通過網絡連接的數據存儲節點上,以獲取更大的存儲容量和更高的并發訪問量。
并行數據庫主要由執行引擎、存儲引擎和管理功能模塊組成。 在這里我簡單介紹幾種常見的多節點數據庫架構,有些甚至可以看做是分布式數據庫的變種,分布式數據庫和我們平時經常提到的數據庫集群有些相似的地方,但是不能把它們混淆。為了讀者更清楚的理解,我做一些簡要說明:
第一類:主從結構數據庫
主從架構的數據庫目前應用比較廣放,其邏輯結構是一個主數據庫節點和一個從數據庫節點組成。從數據庫節點通常可以進行只讀訪問,通過支撐分析行任務來分擔主數據庫節點的壓力。常見的 DB2、Oracle、MySQL等都有主從架構的功能。
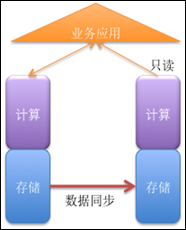
第二類:多計算節點、存儲共享架構
這種架構的數據庫在計算層面采用多節點的方式,但是存儲節點仍然是一個共享架構,所以這種架構的數據庫最大的問題在于可擴展性的限制,對于大數據量、高并發的場景很容易觸發這種架構的理論缺陷閥值。這種架構最杰出的代表是 Oracle RAC以及 DB2 PureScale等數據庫。
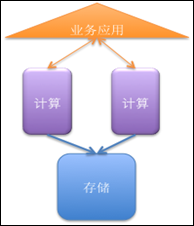
第三類:單引擎節點、無數據共享的分布式架構
這種架構的數據庫會把所有的數據分布到不同的節點上,通過主引擎節點分發任務到所有計算節點,從屬引擎節點作為備用和主引擎節點進行數據同步。代表性產品例如: IBM DB2 DPF、Netezza 等。這些分布式數據庫通常應用于OLAP為主的BI分析領域,因為查詢性能很強,但是對于OLTP 這些數據庫的增、刪、改以及對事物的支持能力較弱。
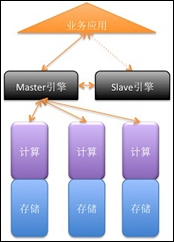
第四類:完全集群化的分布式架構
在這種架構下引擎節點、計算節點以及存儲節點都是無中心的分布式架構,這樣的中心Master架構在組成大規模集群時優勢明顯,我認為這是未來最先進的分布式集群架構,這樣在提供良好的系統擴展性和高可用的同時,也保持了引擎節點的對等性,整個系統完全沒有單點問題。
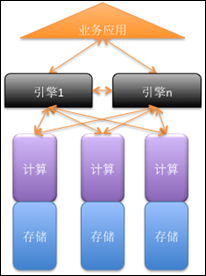
本文標題中所提到的分布式并行數據庫架構,指的就是這里所提到的第三類和第四類數據庫架構,它們在市場上都有很多實際的應用項目。
分布式數據庫的優勢和應用場景
接下來我們簡單介紹一下分布式數據庫架構的主要特點和主要應用場景,請允許我用引跑科技的分布式數據庫產品架構來進行講解,但是,其原理和其他的率屬于第三和第四類分布式數據庫原理和特點是一致的的,所以適合的應用場景也有很多重合的地方。
大家可以忽略引跑 DBOne 數據庫的名字,下面介紹的特點是很通用的。分布式數據庫通常會有以下優勢:
——數據表進行自動分片
——數據的完整性通過多副本技術實現
——高可用性通過分布式結構來保證
——自動的負載均衡
——水平擴展和壓縮
——自動數據分片
基于Share Nothing的分布式數據庫架構,會對數據進行平均分配,通過數據分片(Sharding)的方式分布在不同數據節點。這樣當處理應用對數據的請求時會分布到不同的數據節點并行執行。
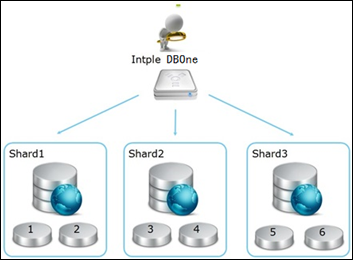
自動數據分片原理圖
設計良好的分布式數據庫系統,會自動根據資源情況進行自動的擴展,把數據和業務負載自動擴展到新加入的物理服務器上。良好的可擴展性也是分布式并行數據庫最大的優勢。
智能水平擴展
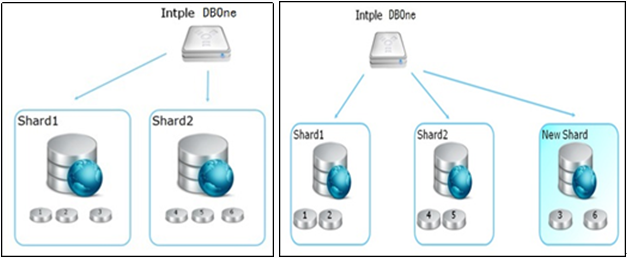
智能水平擴展原理圖
智能水平壓縮
數據水平壓縮是水平擴展的相反操作,用于需要自動或者手動收縮資源的場景。
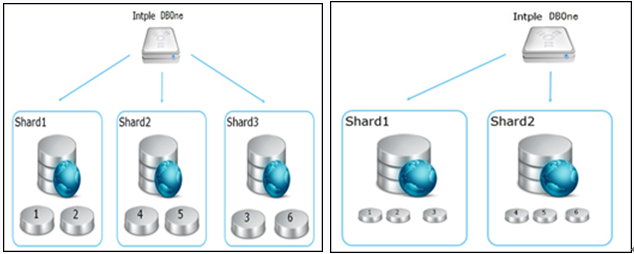
智能水平壓縮原理圖
高可用性
分布式數據庫通常會配置多個數據副本,例如Replica=2時,會把實際數據在不同的物理節點上存儲三份。下面的原理圖,展示了當某個服務器出現故障,其他服務器可以自動接管任務負載,并且重新分配數據分片。

高可用性原理圖二
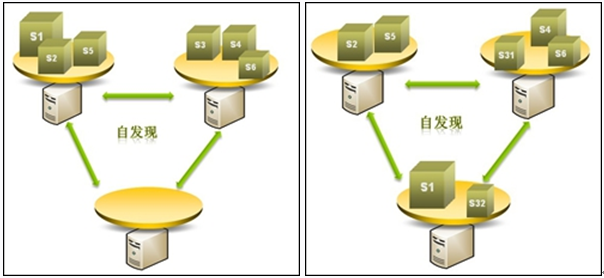
自動節點發現和負載均衡
在分布式數據庫架構中,動態添加硬件資源,從而避免在繁忙時段服務器的過載是非常重要的功能,這樣保證了整體的靈活性和可擴展性大大強于Oracle RAC為代表的傳統交易型數據庫系統。
下圖展示了當服務器出現過載情況時,自動熱遷移數據到空閑物理服務器的情景,整個數據遷移粒度可以是:整個應用級、實例級、Shard級別或Shard內部更細粒度遷移。
綜合來看,分布式并行數據庫在數據處理的高性能、高效的資源利用率、高可用性等方面都有很好的優勢。分布式并行處理機制,對于OLAP領域的應用優勢非常明顯。在OLTP領域分布式并行數據庫還剛剛開始顯現威力,對于分布式事物的支持能力如何,成為判斷分布式并行數據庫是否完善的有效評判標準之一。
OLTP領域使用分布式數據庫的考慮因素
企業的核心業務系統一般都是OLTP為主的應用場景,在這個領域Oracle一直是市場的領導者,緊隨其后的IBM DB2、MS SQL Server等都在這個領域占據重要市場地位。
近年來,隨著開源數據庫的發展,MySQL、PostgreSQL為主的開源數據庫逐步占據了OLTP領域較大一塊市場,在市場份額上對傳統的交易型數據庫廠商造成了沖擊。特別是在互聯網領域,開源數據庫應用非常廣泛。但是,在中大型企業及政府機構領域傳統交易型數據庫三強(Oracle、DB2、SQL Server)仍然占有極大的比重。
隨著國產化戰略、自主可控需求的發展,以及去“Oracle”浪潮不斷的演化,在這些中大型企業中將會逐步使用國內的一些數據庫產品,在其中分布式數據庫是一個非常重要的方向,只有基于好的分布式架構的數據庫才有可能與Oracle RAC進行面對面的直接競爭。
對于企業而言,如果在OLTP應用場景要去Oracle數據庫,還是一個比較大的變革,源于Oracle和上層應用的緊密綁定,所以真正要做去“Oracle”的決定,一般需要考慮以下因素:
1. 變革驅動因素
企業的核心交易系統要想去除掉Oracle,要由足夠的驅動力。這個驅動力或者是國產化、安全自主可控的國家戰略影響,或者是出于降低企業IT成本的需要,無論如何都需要有足夠動力讓企業決策者去推動替換Oracle數據庫的項目。
2. 穩定性因素
OLTP系統通常作為企業核心業務的交易系統,穩定性是第一位的。沒有企業愿意在OLTP應用場景中承受穩定性的損失。即使成本或其他因素再有吸引力,如果穩定性不達標,企業和組織機構頁不會愿意冒這種風險去做變革。對于分布式并行數據庫這種產品來說,把穩定性放在第一位是絕對正確的選擇。
3. 遷移復雜度
Oracle在去IOE運動中是最為復雜和困難的,其原因就在于Oracle數據庫和上層應用綁定比較緊密,替換數據庫需要涉及到應用遷移,這個工作的工作量和時間周期通常較大。
對于上層業務應用來說,如果大量使用Oracle存儲過程、自定義函數、觸發器等來實現負責的業務邏輯,那么替換Oracle數據庫時將會非常耗時,復雜度較高、風險也比較大。
相反,如果業務應用使用Hibernate等比較成熟的開發架構,業務邏輯都封裝在應用層,那么這類應用的遷移難度和復雜度就會比較低,這類應用進行數據庫遷移會比較容易。
4. 高性能
很多大型的業務應用系統底層的數據庫基于Oracle RAC,當數據量增大,SQL查詢的業務邏輯很復雜時,這種存儲共享的數據庫架構會受限于其擴展性的低效率和天花板問題,會出現性能瓶頸。對于并發壓力較大、數據量上TB的的業務系統來說,替換Oracle后,需要新的數據庫系統能夠提供很好的性能支撐。這種情況下,分布式并行數據庫基本上成了不二之選。
5.可擴展性
企業核心業務系統通常對可擴展性要求較高,那么作為替換Oracle的新數據系統,在可擴展性方面要有一定的優勢。分布式數據庫在可擴展性方面通常做的不錯,特別是第三類和第四類分布式數據庫。
6. 高可用性
高可用性是指一個系統經過專門的設計,從而減少停工時間,而保持其服務的高度可用性。在這方面傳統的交易型數據庫會通過雙機熱備,多節點等方式來實現。Oracle RAC、DataGuard等都是常見的方式。
而基于分布式并行架構的數據庫系統,通常在高可用性方面做的不錯,通過多個并行計算、存儲節點以及多副本的實現方式,有效的保證了整體系統的高可用性。
7.運維復雜度
企業IT運維是保證IT能力正常支撐企業業務發展的重要流程,在OLTP應用場景中替換原有的數據庫,會對企業IT的運維能力造成沖擊和挑戰,因此,企業在整個去“Oracle”過程中需要有效的評估運維復雜度的變化。新的基于分布式架構的數據庫如果能夠在用戶界面、使用方式、命令、語法等方面和原有的Oracle數據庫保持盡可能多的兼容,會有效減少企業對新技術的學習成本,使得運維的復雜度可控。
分布式數據庫取代Oracle的常見應用方案
引跑科技DBOne是基于分布式并行數據庫架構的,如下圖展示的架構圖,可以很清楚的看到它是我前面提到的第三類或第四類分布式數據庫架構。因為,它的引擎節點可以部署成主備結構或者完全對等的集群結構。
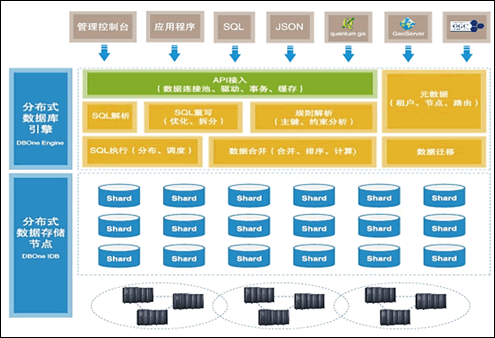
DBOne分布式數據庫架構圖
DBOne主要包括分布式數據庫引擎和分布式數據存儲節點。分布式數據庫引擎是系統核心,其負責SQL解析、優化、路由、分發、合并等操作,同時將底層的眾多存儲節點管理起來;分布式存儲節點使用引跑自行設計和完全自主可控的單機iDB(Intple DB)關系型數據庫產品。用戶可靈活構建不同規模的數據庫集群,通過將業務數據分片到不同的數據庫存儲節點中,極大降低了普通數據庫面對海量數據時的壓力;通過將用戶的SQL請求分發到各節點上執行,充分利用各節點的計算資源,從而能夠使PC服務器集群達到并超越小型機、中大型機的性能。
下面我以引跑的DBOne分布式并行數據庫為例,來介紹一下分布式數據庫在取代Oracle的過程中的常見應用場景。
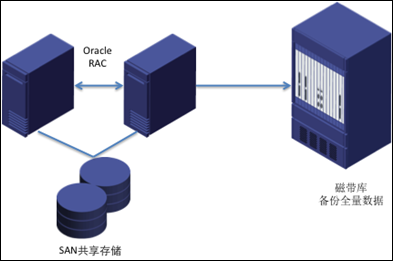
如上圖所示,這是一個典型OLTP應用場景中的Oracle架構,多RAC節點的共享存儲架構模式,本地一般通過帶庫進行定期備份。如果替換這樣的Oracle數據庫,可以采用以下的兩種應用方案。
方案一 Fusion混合模式

在這種架構下,原有Oracle數據庫和分布式數據庫并行運行,通過同步工具進行異步或同步模式的數據同步。把上層應用對數據庫的請求進行劃分,把少量OLTP以及OLAP業務請求分流到分布式數據庫執行。這樣對于某些應用遷移復雜度高、風險較大的情況可以靈活進行處理。如果原有的Oracle數據庫存在性能問題以及存儲擴容的需求,那么可以只在Oracle數據庫中保留“熱”數據,全量數據放在分布式數據庫中,這種模式可以很好的解決用戶的這些頭疼問題。
這種架構是一種在實際項目中經常用到的模式,對很多企業用戶來說,混和模式從各方面來說都更容易接受,盡管它只是一個中間模式,卻能通過較小的代價快速解決客戶的問題。當然,應用負載的分流復雜性問題也是存在的。
方案二 完全分布式模式
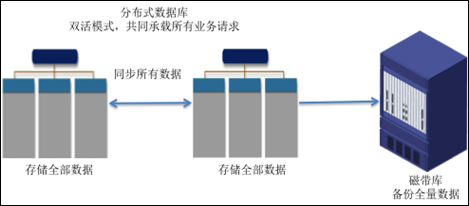
如上圖所示,在這種分布式數據庫架構模式中,數據完全遷移到新的分布式數據庫中,通過兩個相對獨立的分布式集群來實現本地或者異地的數據庫容災。對于很多新的應用項目這是比較好的實現方式,因為無需考慮上層應用遷移的復雜度和風險問題。從實際市場情況來說,這種新交易型應用項目直接采用分布式數據庫是比較常見的的,這種直接去Oracle的方式無論從風險和成本上來說都比較有優勢。
大數據應用促進“分布式架構”的繁榮
從實際市場反饋來說,分布式并行數據庫要想取代Oracle仍然任重而道遠,這其中有很多原因,就像我在第四節提到的那些因素,都制約著國產分布式并行數據庫的發展。
好消息是大數據應用的繁榮會促進分布式并行數據庫的進步,因為整個大數據應用架構都是以分布式以及并行為核心的。越來越多的企業正在探索和實踐大數據項目,隨著大數據應用規模不斷發展和影響力的擴大,對于分布式并行數據庫的發展有極大的促進作用。
我期待有一天能夠在不改變任何原有業務邏輯和代碼的前提下,實現底層分布式數據庫的自由伸縮和擴展。我們會以“高穩定性、可擴展,高性能”為核心理念,改進引跑的分布式并行數據庫,最終我們一定能夠讓它在去Oracle的征途上越走越遠。
相關閱讀
- AI+大數據推動創新與變革02-13
- AI+大數據在數字化轉型中的應用02-13
- 深入探討AI與大數據在數字化轉型中的角色02-13
- 大數據時代,數據可視化的挑戰01-18
- 揭秘數據可視化,贏在大數據時代01-18





-
全國報名服務熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377
京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377